ビッグデータの「その先」にあるデータ仮想化ソリューションって何だ?【前編】:IT導入完全ガイド(1/3 ページ)
データ仮想化ソリューションが求められる背景とその仕組みを基礎から解説する。
数年前より注目され、ビジネス活用が始まりだした「ビッグデータ」だが、ビッグデータの分析が自社のビジネスに役立つと思っていない、もしくはまだまだ実務に応用できるのは先だと考えている企業も多いのではないか。
しかし、既に「その先」を見据えた動きが出てきている。それが「データ仮想化」だ。データ仮想化ソリューションは、ビッグデータをもデータリソースの1つとして取り込み、ビジネスに関わるあらゆるデータを横串に刺すというものだ。データ仮想化ソリューションの概要や求められる背景、導入によってもたらされるであろうメリットなどについて、前後編にわたって検証することとしたい。
データ仮想化が求められるようになった背景
データ仮想化ソリューションとはどのようなものかを説明する前に、まずはこのようなソリューションが必要となったいきさつを追ってみたい。
背景として最も大きいのは、ビッグデータに代表されるような、ビジネスにおけるデータ活用へのニーズの高まりだ。企業ITの歴史を振り返れば、これまで重きが置かれてきたのは業務の効率性や生産性、安定性の追求であり、いかにコスト削減や業務プロセスの最適化を実現するかであった。それが今では、市場競争の激化やビジネスとITのさらなる一体化などを受けて、ITの役割はいかに売上増大に直接的に貢献するかに変わってきているのだ。
そうなると、システム側で取り扱うデータも、以前は財務会計や人事給与といった基幹系のみで良かったものが、例えばサプライチェーン全体にまつわるデータ、さらには顧客の市場動向に関するデータといったものまで含まれるようになりつつある。こうしてさまざまなデータを活用しながら、売れるタイミングで売れる製品を確実に市場に投入するなどといった成果を追求することが、現在の企業ITには強く求められているのである。
しかしこのようにITに対するニーズが大きく変化してはいるものの、現実を見ると企業でのデータ活用はそれほど進んでいるとはいえない。ITRが実施しているIT投資動向調査の結果を見ても分かるように、「情報、ナレッジの共有、再利用環境の整備」「全社的なコンテンツ管理インフラの整備」「マスターデータの統合」といったデータ活用に関する取り組みに関して、重要度は常に上位に位置し、将来的に取り組みたいと考えているにもかかわらず、その実施率は遅々として上がっていないのだ。
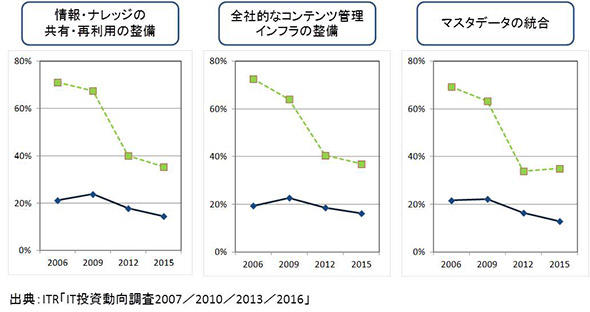 図1 遅々として進まないデータ活用環境の整備(出典:ITR)
図1 遅々として進まないデータ活用環境の整備(出典:ITR)では、意欲はありながらも実際にはデータ活用がそれほど進んでいないのはなぜなのか。企業の資産としてデータはまだまだ定着していないという理由が大きいのではないかと考えられる。
現在では企業の資産は従来の「ヒト(Man)、モノ(Material)、カネ(Money)」の「3M」に、新たに情報(=データ)も加わったといわれている。だが、ヒト、モノ、カネについては、それぞれ人事部門、生産管理や在庫管理部門、財務会計や経理部門といった専門の部門が存在しているのに対し、「データを組織横断的に管轄する部門」というのはほとんどの企業では設けられていない。
一見それに該当するかに思われる情報システム部門も、多くの場合あくまでデータを入れる「箱」を管轄しているにすぎず、データそのものの利活用については担当外といえる。こうしてほとんどの企業では、データはそれぞれの業務システムごとに使われるだけでサイロ化されており、口では“データは資産”と言いつつも、全社的にデータを管理することのできる体制は整ってはいないというのが実態なのである。
 図2 資産として管理されていないデータ(出典:ITR)
図2 資産として管理されていないデータ(出典:ITR)しかしこうした状況にありながらも、少し前に「ビッグデータ」が流行語のようになったことに象徴されるように、企業はより複雑なデータの使い方への関心を高めている。そしてビッグデータを分析してビジネスでの意思決定をよりスピーディかつ正確に行おうとするのであれば、当然ながら蓄積された多種多様なデータにアクセスできなければ話にならない。それもビッグデータのような膨大な量のデータでありながらも、必要な時に瞬時にアクセスすることが求められるのである。
これまでデータ分析のための基盤には、主にデータウェアハウスが用いられてきた。そこでは、企業の基幹系システムなどに蓄積されたデータをETL(Extract、Transform、Load)ツールによって抽出し、利用しやすい形に加工した上で1つのデータベースに蓄積するというアプローチが一般的であった。
しかし、上述のように取り扱うデータの種類と量が大幅に拡大したことで、全てのデータを物理的に1つのデータベースに統合するというのは現実的ではなくなってきたのである。例えば顧客に関するデータにしても、直販する部門であれば顧客=エンドユーザーであるのに対し、間接販売の部門であれば顧客は代理店などを指すことが多い。このように定義が異なる顧客データを1つに統合するというのは容易なことではない。
これまで、このような場合には、BIツールなどで分析を行うごとにその時々の使い方に応じてツール側で一時的にデータの定義に整合性を取るような方法が一般的であったが、これではデータの再利用はできず、時間と手間もかかってしまう。そこで、データソースは物理的に分散されたまま、それぞれのデータを論理的に統合してリアルタイムに使えるようにしようという発想が出てきた。これこそが「データ仮想化」なのである。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- 「君が欲しい」と言わせる情シス資格 キャリアチェンジ向きの資格も解説
- 脱PPAPはどれほど進んだ? 無意味な理由や代替案も解説【メールセキュリティ調査】
- さよなら、8ビットCPU「Z80」:757th Lap
- Zoomの新コラボレーションプラットフォーム「Zoom Workplace」って何?
- SansanがAI群雄割拠時代に「Notion AI」の活用に力を入れる理由
- レガシーERPに比べて変化に強い「コンポーザブルERP」の基本と活用方法
- 今やITパスポートより人気の“あの資格” IT資格取得意向を調査
- 「Microsoft 365」人気のプランはどれ? 勤務先で契約中のプランと利用料を聞いてみた
- 初心者向け、コピペで使えるChatGPTプロンプト(第7回)
- MicrosoftがTeamsを365製品から分離 日本での価格と注意点は?
編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。