バグは本当に金曜日に生まれるのか、分析手法「MSR」とは?:5分で分かる最新キーワード解説(1/3 ページ)
ソースコードなど開発関連の膨大な電子化情報を分析する新たなマイニング手法「MRS」が登場した。バグ予測やコード再利用に使えるのか。
今回のテーマは「MSR(Mining Software Repositories、ソフトウェアリポジトリマイニング)」だ。ビッグデータ解析技術により、ソフトウェアの開発技術を変革する新しいトレンドが生まれようとしている。
「MSR/ソフトウェアリポジトリマイニング」とは?
MSRは、ソフトウェアのソースコードやドキュメント、開発や運用、保守プロセスで発生した議論の記録など、ソフト開発に関連して蓄積された膨大な電子化情報の中から、新しいソフトの設計、開発、保守に利用可能な知見を抽出して活用し、ソフト開発の生産性、品質、保守性の向上を目指す新しい知識再利用技術だ。
「マイニング」(Mining、採鉱)技術としてよく知られるのはデータマイニング技術だろう。小売店の販売データを分析して「ビールを買う顧客が一緒に買う商品は紙おむつ」であるという一見不思議な相関関係が見つかったという有名なエピソードが語るように、業務データを見ているだけでは分からないデータ間の相関関係や傾向を導き出し、販売予測やマーケティングに役立てる分析技術のことだ。
MSRも同様に、膨大に蓄積されたデータの中から役に立つ情報を取り出そうとする技術だ。ただし、分析の対象とするデータの種類が違う。データマイニングが業務データを対象にするのに対しMSRはソフトウェアに関連するあらゆる情報を分析する。
図1に見るように、ソースコードはもちろんのこと、CVS(Concurrent Versions System、ファイルのバージョン管理システムのデータ)やSVN(Subversion、オープンソースのバージョン管理ツールのデータ)、バグ報告(バグトラッキングシステムのデータやその他の資料)、クラッシュログ、実行履歴、メール(SNSやブログ、掲示板なども含む場合がある)などがマイニングの対象だ。
それらのデータは構造化されてデータベースに格納されるものもあれば、文書やテキストなどの非構造化データとして蓄積されるものもある。共通点は電子化されているということだけかもしれない。それらを一元的に「リポジトリ」という、いわば貯蔵庫に入れて、さまざまなアルゴリズムを駆使して分析するのがMSRの方法だ。
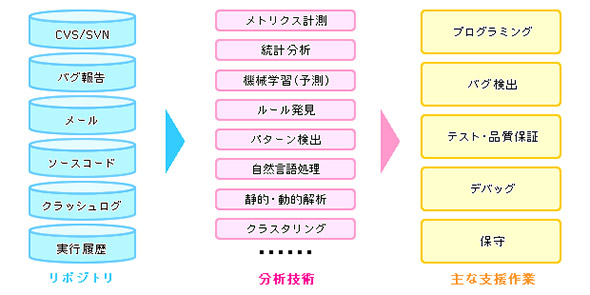 図1 「MSR」の概要(出典:ソフトウェアジャパン2013、ITフォーラムセッション「ソフトウェアリポジトリマイニングの技術動向とその応用」(奈良先端科学技術大学院大学 門田暁人))
図1 「MSR」の概要(出典:ソフトウェアジャパン2013、ITフォーラムセッション「ソフトウェアリポジトリマイニングの技術動向とその応用」(奈良先端科学技術大学院大学 門田暁人))MSRがあらためて注目される背景
MSRは、実証的ソフトウェア工学(Empirical Software Engineering)の1つのアプローチとして、十数年前からアカデミズムの世界で研究されてきた。それが今、あらためて注目されるのは、コンピューティング能力の指数関数的な増大とともにソフトウェアに関連する電子化情報が爆発的に増大してビッグデータ化したことが背景にある。
例えば、今回取材したNTTデータでは、直近7年間で300Mステップに及ぶソースコードが蓄積され、あるプロジェクトでは開発関連ドキュメントが数千万ファイルにものぼる。これに加え、Web上には少なくとも1億ページ以上の技術情報ページがあり、数千万ファイルのオープンソースのコードが存在するといわれている。
構造化データと非構造化データが混在する多様なデータが日々生まれては蓄積される中で、一方ではビッグデータ分析技術も近年急速に成熟した。例えば、コード解析、データマイニング、テキストマイニング、統計解析、パターンマッチング、自然言語処理、ソーシャルネットワーク分析、機械学習などといった技術により、従来はITが扱い切れなかった量と種類のデータが、今のところそれぞれ限界はあるにしても、全て分析可能になった。今こそ、開発資産のマイニングが現実的なメリットを生むのではないかという期待が高まっているのだ。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- 「雨の日しかWi-Fiが使えない」 原因は意外なアレだった:755th Lap
- コンプラブームなんてウソだった 一番の「人間関係の困りごと」が判明
- 多要素認証はこうして突破される 5大攻撃手法と防御策
- 「ログイン処理、癖が強い……」Microsoft 365プラン別に見る課題まとめ
- “脱”Excelデータ分析 データドリブン組織への変革ステップを解説
- 2023年もWindows 11は「様子見」、Microsoftの“賭け”が失敗した原因は?
- MicrosoftがTeamsを365製品から分離 日本での価格と注意点は?
- まるで聖徳太子の耳のように複数話者を聞き分ける「分離集音」技術とは?
- Sansanの全従業員がミッションに向かい続けるためのツールとは?
- 給与、労働時間の“グレーゾーン”に対する最善の対応とは
編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。