統合プロセッサの潜在能力を引き出すフレームワーク「HSA」とは?:5分で分かる最新キーワード解説(2/3 ページ)
登場した「第4世代」APU
既にAMDは、「Kabini(カビーニ)」「Temash(テマシュ)」の開発コードネームで開発したAPUを「AMD Aシリーズ APU」および「AMD Eシリーズ APU」として発表し、2014年1月に次の第4世代のAPU「Kaveri(カヴェリ)」こと「Aシリーズ」を発表した。
インテルの統合プロセッサではGPUがダイ面積に占める割合は4割程度だが、Aシリーズでは図2に見るように、さらに広い面積をGPUに割く。x86 CPUコアは最大4基のクアッドコアである一方、同一ダイに構成されたGPUは64基のRadeonコアを1クラスタとしたCU(Compute Unit)が最大8基作り込まれるため、旧来のコアの数え方を踏襲すれば512コアを搭載したことになる。なお、AMDは同社のGCN(Graphics Core Next)アーキテクチャのGPUコアとして8基と数えている。これからのGPUの重要性を意識した製品だ。
 図2 AMDのAPU Aシリーズの外観とダイ。オレンジ色に見える部分がGPUだ(出典:日本AMD)
図2 AMDのAPU Aシリーズの外観とダイ。オレンジ色に見える部分がGPUだ(出典:日本AMD)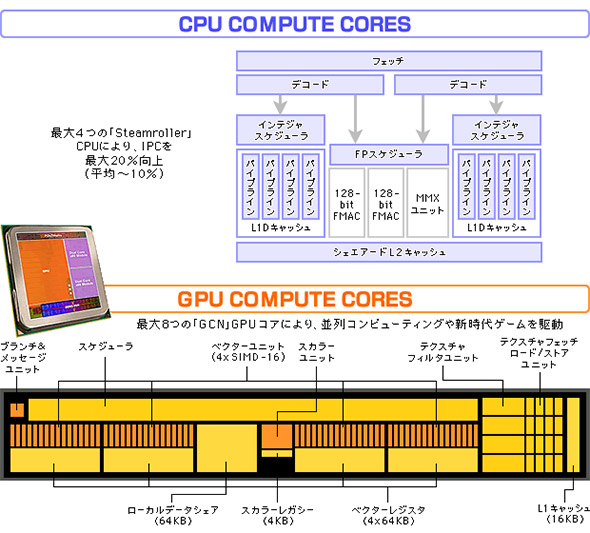 図3 Aシリーズの特徴(出典:日本AMD)
図3 Aシリーズの特徴(出典:日本AMD)統合プロセッサで何が解決されるのか?
このような大規模マルチコア化したGPUとCPUが1つのプロセッサとして構成されることの意味は何だろうか。
もともとCPUは数値演算(シリアルプロセッシング)のために利用し、GPUはCPUからの命令に従ってグラフィックス処理だけを担当するものとして発展した。グラフィックス処理には高速化のために並列演算(パラレルプロセッシング)が用いられる。その能力を長年追求したGPUは並列処理に特化した進化を続け、今では1チップでテラフロップスオーダーの処理性能を持つようになった。
一方でCPUのクロックアップは頭打ちで、性能向上のためにGPUの並列処理能力を利用できないかという要望が強まった。そのためにはCPUとGPUとの間の情報交換ができるだけスムーズに行われる必要がある。統合プロセッサは、単一チップに両者を収めることで両者間の距離を究極まで縮め、高速なデータ転送を実現したわけだ。
残る課題は統合プロセッサの真価を引き出すアプリケーション開発
ところがハードウェアの進化にソフトウェアが追随できていないのが現状だ。CPU用とGPU用のプログラミングは大きく違い、それぞれ別に開発せざるを得ない。CPUとGPUが同一チップ上に載りながら、いわば家庭内別居のような状況なのだ。
そこで両者の間を取り持つ仕組みを作ろうとしたのが、2010年にAppleが提唱し、やがてオープン標準になった「OpenCL」や、独自路線を行くNVDIAの「CUDA」などだ。これらによりGPGPU(General-Purpose computing on Graphics Processing Units)と呼ばれるGPUの並列処理能力を大規模数値演算に応用するのが容易になった。
とはいえ、従来のビジネス系システム開発を行う企業の技術者は、新技術を習得する時間もなければコストもなかなか捻出できない。そこでAMDは、従来のソフトウェア面からのアプローチに加えハードウェア面からのアプローチを加えた、もっと使いやすいヘテロジニアスな統合開発フレームワークを作ろうとしているわけだ。しかも、それをオープン標準にすることでアプリケーション開発のエコシステムを形成しようとしている。
おおまかな仕組みは図4に見るようなものだ。さまざまな高級言語を使う開発環境で作り出されたプログラムは「HSAランタイム」により中間言語である「HSAIL」(HSA Intermediate Language)に翻訳され、さらに「HSA Finalizer」によってGPU固有の命令セット(ISA)へと変換される。
開発言語は、例えばC++、C++ AMP、Objective C、OpenCL、OpenMP、Javaなど技術者が使い慣れたものを使えばよく、また利用するプロセッサが何であってもHSA対応である限りは、CPUとGPUをともに効率的に利用したアプリケーションが作れるというわけだ。
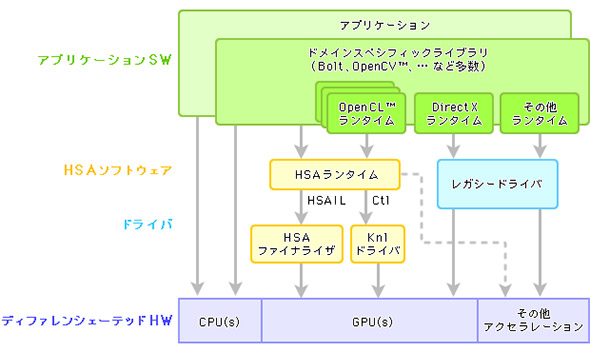 図4 HSAの全体イメージ(出典:日本AMD)
図4 HSAの全体イメージ(出典:日本AMD)関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
製品カタログや技術資料、導入事例など、IT導入の課題解決に役立つ資料を簡単に入手できます。
- TeamsとZoomのシェア事情、ビデオ会議の人気再燃……Web会議トレンドの裏側
- システム導入で大混乱はもう嫌……紙とExcelをやめたい企業の苦肉の策とは
- ギガを食い尽くす、あのスマート家電に要注意:756th Lap
- 存在感を増すオラクルのクラウド事業 ライセンスの収益を上回る
- コミュニケーションツールの導入状況(2015年)
- 2023年もWindows 11は「様子見」、Microsoftの“賭け”が失敗した原因は?
- Zoomの新コラボレーションプラットフォーム「Zoom Workplace」って何?
- グローバル人事格付けはこう決める、カゴメのジョブグレード制度
- 「ワイヤレスファースト」がけん引するネットワーク機器市場 2023年までの展望は?
- Dockerブームはウソだった? 1年たってピタリと止まった導入率
編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。